Corpus contents
The motivation behind the creation of the Nijmegen Corpus of Casual French was to provide large amounts of high-quality recordings of casual speech suitable for phonetic analysis. The uniqueness of our corpus can be characterized as follows:
- It contains around 35 hours of orthographically-transcribed casual conversations elicited following a thoroughly tested procedure (469,484 word tokens, 15,574 word types).
- It contains high-quality recordings captured with head-mounted microphones in a sound-attenuated room.
- It contains speech from 46 speakers (24 female and 22 male) sharing the same geographic and educational background. This allows researchers to study inter-speaker variation.
- It contains large amounts of data for every speaker (around 90 minutes of recorded conversation for every pair of speakers). This allows researchers to study within-speaker variability.
- It contains audio as well as video data, which can be used to study facial and body gestures during verbal communication.
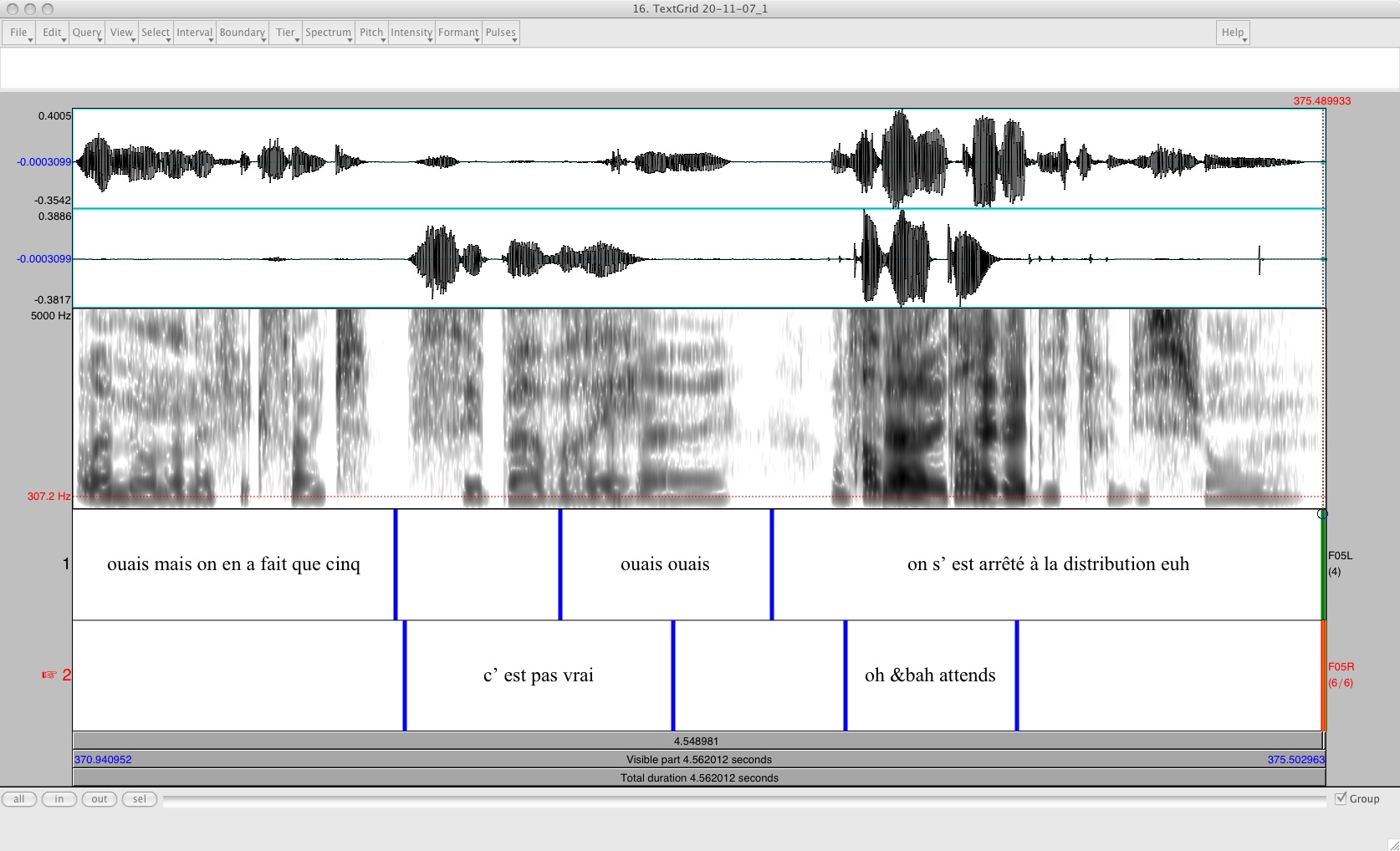
The following screenshot illustrates a short excerpt from one of the conversations in the corpus (click on image for audio):
|